
Transaction: (Part 2: Preventing Lost Updates, Write Skew, Phantoms, Serializable Snapshot Isolation)
Beyond Basics: Mastering Advanced Transaction Management with Lost Updates, Write Skew, Phantom Anomalies and Serializability

Introduction
In the previous part, we laid the groundwork for understanding database transactions, focusing on the critical role of ACID properties in maintaining data integrity, even during complex operations. We also discussed the challenges of weak isolation levels, such as Read Committed, which, while effective in certain scenarios, falls short in preventing anomalies like Read Skew. Snapshot Isolation was introduced as a stronger solution, offering a consistent view of the database throughout the transaction.
As we continue our exploration in Part 2, we will dive deeper into advanced transaction management techniques. We’ll examine how to "Prevent Lost Updates," a common issue in concurrent environments, and explore the complexities of "Write Skew" and "Phantoms," which can lead to subtle but significant inconsistencies in your database. These concepts are essential for anyone looking to master database transactions and ensure robust, error-free operations in multi-user systems. Let's continue this journey into the deeper intricacies of database transactions.
Lost Updates
In database systems, the "lost update" problem is a critical issue that occurs when two or more transactions simultaneously attempt to modify the same data. This typically happens in a read-modify-write cycle, where a transaction reads a value, modifies it, and writes it back. If another transaction does the same thing concurrently, one of the updates may be overwritten or "lost," leading to inconsistencies in the database.
Atomic Write Operations
One of the most effective ways to prevent lost updates is through atomic write operations. These operations allow updates to be applied as a single, indivisible action, ensuring that no other transaction can interfere between the read and write steps. Atomic operations typically use exclusive locks on the data being read, ensuring that no other transaction can access the data until the update is complete. This method guarantees that read-modify-write cycles are executed in a sequential manner, thus avoiding lost updates.
Explicit Locking
In cases where atomic operations are not sufficient or applicable, explicit locking is another approach to preventing lost updates. By manually locking the data before performing a read-modify-write cycle, applications can ensure that no other transactions can access or modify the same data until the lock is released. This approach is particularly useful in complex scenarios where the update logic cannot be expressed as a simple atomic operation, such as in a multiplayer game where multiple players might attempt to move the same game piece simultaneously. However, implementing explicit locking requires careful consideration of the application logic to avoid race conditions and ensure that all necessary locks are applied correctly.
Automatic Detection and Retry
Some database systems are capable of automatically detecting lost updates. Instead of preventing concurrent read-modify-write cycles from occurring, these systems allow the transactions to proceed in parallel but monitor for any conflicts. If a lost update is detected, the system aborts the conflicting transaction and forces it to retry. This method, often used in conjunction with snapshot isolation, can be an efficient way to handle lost updates without requiring explicit locking or atomic operations.
Compare-and-Set
In databases that do not support full transactional capabilities, a common method to prevent lost updates is the compare-and-set operation. This operation allows an update to proceed only if the data has not changed since it was last read by the transaction. If the data has been modified in the meantime, the update fails, and the transaction must retry the read-modify-write cycle. This approach works well in simple scenarios but may not be foolproof if the database does not properly manage concurrent writes.
Handling Lost Updates in Replicated Databases
In replicated databases, the issue of lost updates becomes more complex due to the possibility of concurrent writes on different nodes. Traditional locking mechanisms and compare-and-set operations may not be effective in such environments. Instead, these systems often allow conflicting versions of data to be created, which are later merged by application logic or specialized data structures. For instance, Riak 2.0 employs commutative data types that can merge updates in a way that prevents lost updates, even across replicas. However, not all replication strategies are robust against lost updates; methods like Last Write Wins (LWW) can still result in data loss, which is a significant drawback in many replicated systems.
In summary, preventing lost updates requires a combination of database features and careful application design. Whether through atomic operations, explicit locks, automatic detection, or sophisticated merge strategies in replicated systems, ensuring that all updates are preserved is crucial for maintaining data integrity in concurrent environments.
Write Skew
In the world of database transactions, race conditions like dirty writes and lost updates are well-known threats to data integrity, often occurring when concurrent transactions attempt to modify the same data. However, there's a more nuanced race condition known as write skew, which can arise even when different transactions are updating different objects.
Write skew occurs in scenarios where two or more transactions simultaneously read the same data and then proceed to update different parts of it. Unlike dirty writes or lost updates, where the conflict is straightforward because the same object is being modified, write skew involves a more complex interaction between transactions. This subtlety makes it harder to detect and prevent.
Example
Imagine a scenario where two clients are booking an appointment with a lawyer who maintains an open calendar accessible to all clients. The lawyer's practice is popular, and their calendar fills up quickly. When a client wishes to book an appointment, the system checks the lawyer's available time slots to ensure that no overlapping appointments are scheduled. If the time slot is free, the appointment is confirmed.
Now, consider two clients who both want to book a one-hour appointment with the lawyer at the same time. Under a weaker isolation level like snapshot isolation, each client’s transaction reads the calendar at the same time, sees the desired time slot as available, and proceeds to book it. Since these transactions are isolated from each other, they don’t immediately see the conflicting booking being made by the other client. As a result, both transactions succeed, and the lawyer ends up with two conflicting appointments at the same time—a classic example of write skew.
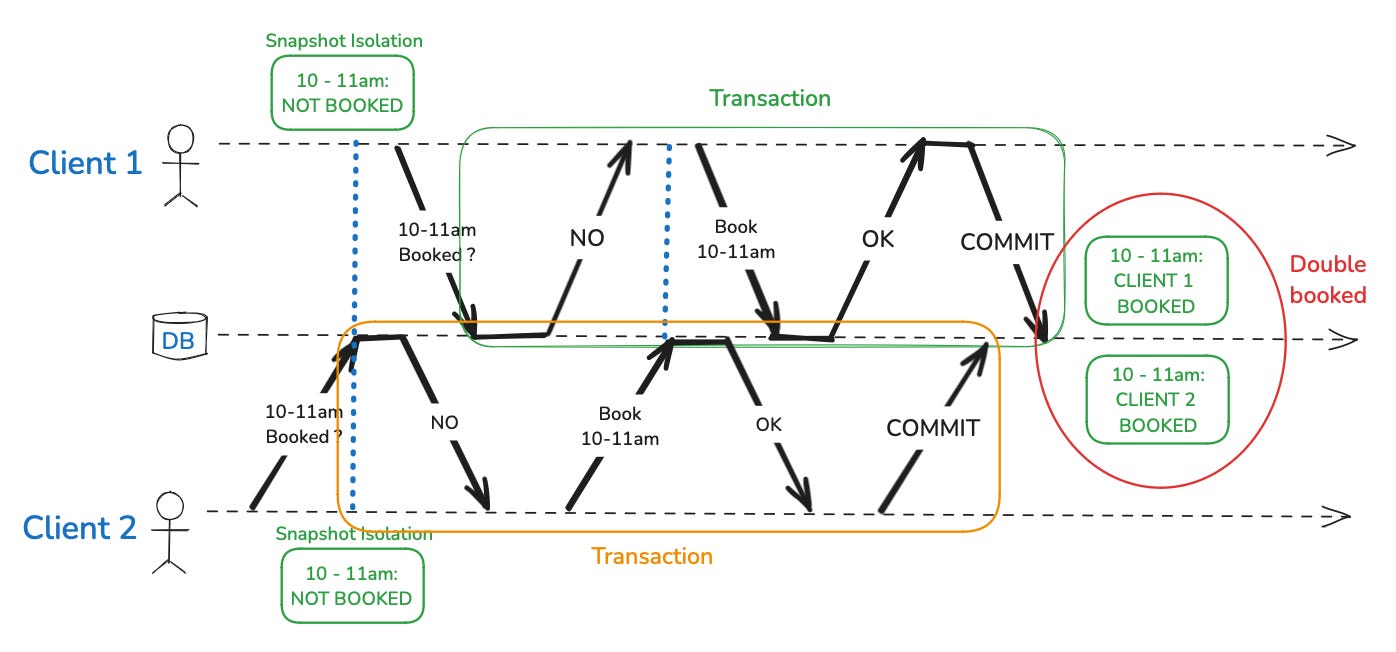
Write skew vs lost update problem
Write skew can be seen as a broader version of the lost update problem. However, unlike lost updates, where straightforward solutions like atomic operations or snapshot isolation can help, preventing write skew requires more sophisticated measures. The challenge lies in the fact that write skew often involves multiple objects, making single-object atomic operations ineffective. Furthermore, the automatic mechanisms that detect and prevent lost updates in some database systems do not cover the complexities of write skew.
Solution to write skew
To effectively guard against write skew, a serializable isolation level is typically required. This ensures that transactions are executed in a way that is equivalent to some serial order, preventing the subtle inconsistencies caused by write skew. In cases where serializable isolation isn't feasible, another approach is to explicitly lock all the rows that a transaction depends on, though this can lead to performance bottlenecks and increased contention.
In summary, write skew represents one of the more elusive challenges in maintaining data integrity during concurrent transactions. Its subtlety necessitates careful consideration of the isolation level and transaction management strategy to prevent unintended consequences, such as conflicting updates that could disrupt the lawyer's appointment schedule.
Serializability
In the complex landscape of database transactions, serializability stands out as the gold standard for ensuring data integrity and consistency. At its core, serializability guarantees that the outcome of concurrently executed transactions is indistinguishable from some serial execution of those transactions. This means that even though transactions may run in parallel, their effects on the database are as if they were executed one after the other in a specific sequence.
The key advantage of serializability is that it eliminates all possible race conditions. Whether it’s a lost update, write skew, or a phantom read, serializability ensures that such anomalies do not occur. This strong guarantee provides a foundation for building reliable and robust database applications.
However, the benefits of serializability come at a cost. Implementing serializable isolation can be challenging, and the performance trade-offs are significant. Most databases use one of three main approaches to achieve serializability.
Actual Serial Execution
The simplest, yet most drastic approach is to execute transactions one at a time, in a strict serial order. By completely eliminating concurrency, this method inherently avoids any race conditions. While this approach is straightforward, it severely limits throughput, as it relies on a single thread of execution. This method is feasible in scenarios where transactions are short and all data is in memory, as seen in systems like VoltDB and Redis.
Used by: VoltDB, Redis, and Datomic.Datomic
Two-Phase Locking (2PL)
For many years, two-phase locking was the standard method for achieving serializability in databases. In this approach, transactions acquire locks on the data they access, and these locks are held until the transaction completes. The locking process ensures that no other transaction can access the same data in a conflicting way until the first transaction is finished. While effective, two-phase locking can lead to performance bottlenecks due to the overhead of acquiring and releasing locks, as well as potential deadlocks.
Predicate Locks: To enforce serializability, 2PL uses predicate locks, which are more generalized than traditional row or object locks. Instead of locking a specific row or object, a predicate lock locks all objects that match a certain condition (e.g., all rows where
room_id = 123). This prevents other transactions from modifying any data that might affect the locked predicate, ensuring that even objects that do not yet exist but could match the condition in the future are protected. This is particularly important in preventing anomalies like write skew and phantoms, where the existence of new data could violate the consistency expected by ongoing transactions.Index-Range Locks: Although predicate locks provide strong guarantees, they can be expensive to implement due to the complexity of checking conditions across potentially large datasets. To mitigate this, many databases use index-range locks as a more efficient approximation. Index-range locks restrict access to a range of values in an index, effectively locking a portion of the data that matches a broader condition. While not as precise as predicate locks, index-range locks offer a good balance between performance and isolation, preventing many of the same anomalies by ensuring that no conflicting operations can occur within the locked range.
Used by: MySQL, SQL Server, Oracle Database and IBM DB2
Serializable Snapshot Isolation (SSI)
While snapshot isolation is good for performance, its inability to prevent anomalies like write skew or phantoms (where a transaction reads a set of rows matching a condition, but other transactions insert rows that match the same condition later) can be problematic in scenarios requiring strict consistency. This is where SSI comes in—it aims to detect and prevent these anomalies while maintaining the performance characteristics of snapshot isolation.
A more modern approach is Serializable Snapshot Isolation, which combines the performance benefits of snapshot isolation with serializability guarantees. Unlike two-phase locking, SSI is an optimistic concurrency control technique, where transactions are allowed to proceed without acquiring locks. The database checks at commit time whether any conflicts occurred. If a conflict is detected, the transaction is aborted and must be retried. This approach offers a good balance between performance and the strong guarantees of serializability. SSI enhances snapshot isolation by adding mechanisms to detect when the execution of concurrent transactions would lead to a result that is not serializable. It does this through two main techniques:
Detecting Stale MVCC Reads
Multi-Version Concurrency Control (MVCC) underpins snapshot isolation by allowing transactions to read from a consistent snapshot of the database, ignoring uncommitted writes from other transactions. However, if a transaction reads data that was later modified by another transaction, it might be operating on outdated information.
SSI tracks when a transaction reads a version of an object that might have been updated by another transaction. If, by the time the first transaction tries to commit, the data it read has been modified by another committed transaction, SSI will detect this and abort the transaction to prevent non-serializable outcomes.
Detecting Writes That Affect Prior Reads
Another critical issue arises when a transaction writes to the database based on data it has read earlier. If another transaction modifies this data after the read but before the write, it can lead to inconsistencies.
To handle this, SSI checks for conflicts where a write operation in one transaction affects data that was read by another transaction. Instead of blocking these operations like traditional locking mechanisms, SSI uses a "tripwire" approach. When a transaction writes data, it checks for any other transactions that have recently read the same data. If such transactions exist, SSI flags them, and if they are still active when the write occurs, the conflicting transaction might be aborted.
Used by: PostgreSQL, FoundationDB
Conclusion
In this two-part series, we've journeyed through the intricate landscape of database transactions, exploring the fundamental principles that ensure data consistency and integrity in multi-user environments. We began with the foundational concepts of ACID properties, highlighting how they form the bedrock of reliable transaction processing. From there, we delved into various isolation levels, such as Read Committed and Snapshot Isolation, uncovering their strengths and limitations, particularly in preventing anomalies like Read Skew.
In Part 2, we shifted our focus to the more nuanced challenges of concurrency, examining the dangers of lost updates, write skew, and phantoms—issues that weaker isolation levels struggle to prevent. We explored advanced techniques like Serializable Snapshot Isolation, which provides robust guarantees of serializability without sacrificing performance. Additionally, we discussed the role of predicate locks and index-range locks in enforcing serializability within the Two-Phase Locking (2PL) framework.
As you continue to design and build database systems, understanding these concepts will empower you to make informed decisions about the trade-offs you're willing to make. Whether you prioritize performance or consistency, the key is to be aware of the implications of your choices and to tailor your approach to the specific needs of your application.
By mastering the principles discussed in this series, you'll be well-equipped to navigate the complexities of database transactions, ensuring that your systems remain robust, reliable, and ready to handle the challenges of concurrent processing in a multi-user world.
Copyright Notice
© 2024 trnquiltrips. All rights reserved.
This content is freely available for academic and research purposes only. Redistribution, modification, and use in any form for commercial purposes is strictly prohibited without explicit written permission from the copyright holder.
For inquiries regarding permissions, please contact trnquiltrips@gmail.com