
Stream-Processing: How Real-Time Data Processing is Transforming Technology (Part 1)
Unlock the power of real-time data processing with stream-based architectures driving instant insights and seamless scalability.

Introduction
In today's hyper-connected world, data doesn't sleep. Every click, swipe, and transaction generates a stream of information that businesses can harness to gain real-time insights and deliver instant value to users. Companies like Meta and Netflix have pioneered ways to process this relentless flow of data efficiently, shifting from traditional batch processing to sophisticated stream processing systems.
In this blog, we'll explore the evolution of data processing, delve into the mechanics of stream processing, and understand how event-driven architectures are reshaping the way we interact with data.
The Limitations of Batch Processing
Batch processing has been a staple in data management for decades. It involves collecting data over a period, such as a day, and processing it all at once. While effective for certain tasks, batch processing assumes that the data set is complete and finite before processing begins.
Why Batch Processing Falls Short
Delayed Insights: In a fast-paced environment, waiting hours or days for data processing means missed opportunities.
Inefficiency with Unbounded Data: With continuous data generation, like user interactions on a social media platform, batch processing can't keep up in real-time.
Imagine a security system that only reviews surveillance footage once a day. Any incidents occurring in between would go unnoticed until the next batch processing cycle.
Embracing Stream Processing
To address the shortcomings of batch processing, stream processing has emerged as a powerful paradigm. It involves processing data in real-time, as soon as it arrives.
Benefits of Stream Processing
Immediate Insights: Allows businesses to react instantly to new information.
Efficiency with Continuous Data: Ideal for applications where data is constantly generated.
Netflix uses stream processing to monitor user activity and recommend content in real-time, enhancing user engagement and satisfaction.
Understanding Event Streams
At the core of stream processing are events—individual records representing something that happened at a specific time.
Characteristics of Events
Immutable: Once an event occurs, it doesn't change.
Time-Stamped: Each event includes a timestamp indicating when it happened.
Self-Contained: Contains all necessary information about the occurrence.

Think of events as tweets on Twitter. Each tweet is an immutable record that can be processed and analyzed in real-time.
Messaging Systems: The Backbone of Stream Processing
To facilitate the flow of events from producers to consumers, messaging systems are employed. They ensure reliable, efficient, and scalable transmission of data.
Direct Messaging vs. Message Brokers
Direct Messaging:
Definition: Producers send events directly to consumers via network protocols like TCP or UDP.
Pros: Low latency, straightforward implementation.
Cons: Not scalable for multiple consumers, less fault-tolerant.
Message Brokers:
Definition: Intermediary systems that manage event transmission between producers and consumers.
Pros: Scalability, fault tolerance, and the ability to handle multiple producers and consumers.
Cons: Slightly increased latency due to the intermediary step.
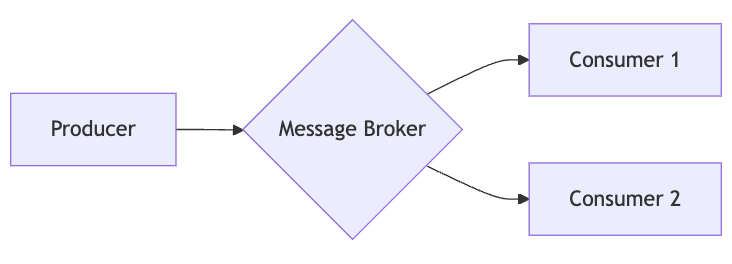
Meta uses Apache Kafka, a popular message broker, to handle billions of real-time events, ensuring data is efficiently routed to various services.
Handling Overload and Failures
Challenges in Messaging Systems:
Overwhelmed Consumers: When producers send data faster than consumers can process.
System Failures: Nodes crashing or going offline.
Solutions:
Buffering: Temporarily storing events in a queue.
Backpressure: Slowing down producers when consumers are lagging.
Message Acknowledgments: Ensuring messages are processed by consumers before removal from the queue.
Replication and Durability: Duplicating messages across systems to prevent data loss.
Partitioned Logs: Scaling Stream Processing
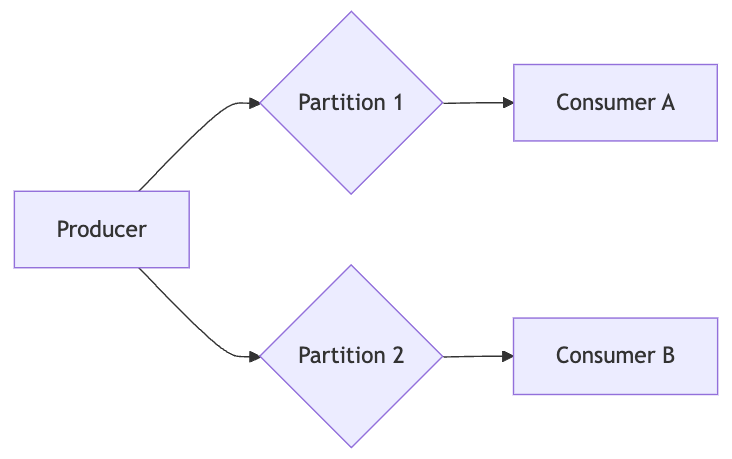
To manage high volumes of data, messaging systems implement partitioned logs, which divide data streams into segments that can be processed in parallel.
How Partitioned Logs Work
Partitioning: Splitting the event stream into multiple partitions, each an independent, ordered log.
Offsets: Each event in a partition is assigned a unique, sequential offset.
Parallelism: Consumers can process different partitions simultaneously.
Consumer Offsets and Message Ordering
Consumer Offsets:
Track the last processed event's offset.
Allow consumers to resume from the correct point after failures.
Message Ordering:
Within Partitions: Events are strictly ordered.
Across Partitions: No guaranteed order.
If Consumer A processing Partition 1 fails after Offset 100, a new consumer can pick up from Offset 101, ensuring no events are missed or duplicated.
Integrating Databases with Streams
To maintain consistency across systems, it's crucial to synchronize databases with event streams.
Change Data Capture (CDC)
Definition: CDC is a technique for capturing changes made to a database and delivering them as a stream of events.
How CDC Works:
Monitoring: CDC tools watch the database's transaction log.
Event Generation: Each change (insert, update, delete) becomes an event.
Propagation: Events are sent to downstream systems like caches, search indexes, or analytics platforms.
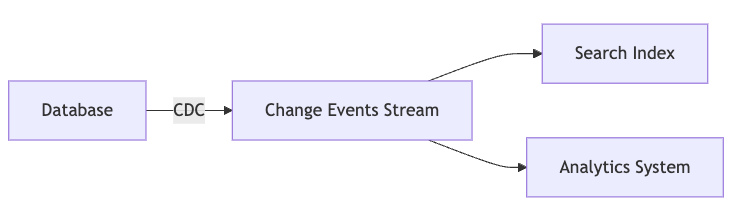
Ensures that all systems reflect the most current data without manual intervention.
Event Sourcing
Definition: Event sourcing is an architectural pattern where all changes to application state are stored as a sequence of events.
Key Concepts:
Immutable Events: Every state change is an event that is stored indefinitely.
State Reconstruction: The current state is derived by replaying the event log.
Difference from CDC: While CDC captures changes from an existing database, event sourcing builds the system around the event log itself.
In a financial application, every transaction (deposit, withdrawal) is an event. The account balance is calculated by replaying all these events.
Benefits:
Auditability: Complete history of all changes.
Flexibility: Ability to rebuild state in different ways for new features.
Conclusion
The shift from batch processing to stream processing represents a fundamental change in how we handle data. By processing events in real-time, businesses can deliver timely insights, enhance user experiences, and stay competitive in a rapidly evolving landscape.
Companies like Meta and Netflix have demonstrated the power of embracing stream processing architectures. By integrating messaging systems, partitioned logs, and event-driven designs like CDC and event sourcing, they can process vast amounts of data efficiently and reliably.
Final Thoughts: As data continues to grow exponentially, adopting stream processing isn't just advantageous—it's becoming essential. By understanding and implementing these concepts, organizations can unlock the full potential of their data in the real-time world.