
Navigating the Chaos: Understanding Faults in Distributed Systems
Discover the hidden complexities of distributed systems and learn how to build resilient software that thrives in the face of network failures, partial crashes, and unpredictable behavior.

Introduction
Distributed systems are a complex yet essential aspect of modern computing. Unlike software running on a single computer, distributed systems face unique challenges, primarily due to their reliance on unreliable networks, inconsistent clocks, and partial system failures, that make them unpredictable and difficult to manage. This blog aims to break down some of these challenges, explaining why they occur and how they impact system reliability.
Partial Failure
In a single-computer program, errors usually result in a clear outcome: the program either works or it fails. This predictable behavior is due to the fact that computers are designed to operate with mathematical precision. When errors occur, the system often crashes to prevent incorrect results. In contrast, distributed systems operate in a more unpredictable environment where multiple computers (nodes) are interconnected via a network. In distributed systems, some parts can fail while others continue to work, a scenario known as a partial failure. For example, one node in a system might crash or lose network connectivity while other nodes continue functioning. This partial failure is non-deterministic, meaning that its occurrence and behavior are unpredictable. This uncertainty makes distributed systems challenging to manage.
Unreliable Networks
Networks in distributed systems are unreliable by nature. Unlike a single computer, where data and memory are self-contained, distributed systems rely on networks for communication. Here are some common network issues:
Packet Loss: Messages sent between nodes may get lost due to network issues.
Delays: Messages can be delayed because of network congestion.
Node Failures: Nodes may crash or become temporarily unresponsive.
Uncertain Outcomes: Even when sending a message, there's no guarantee it will reach its destination or that a response will come back.
Network faults are not just theoretical; they happen in real-world systems, including large-scale data centers. Some common types of network faults include:
Network Partitions: When a part of the network becomes isolated from the rest, making communication impossible.
Hardware Failures: Issues like power distribution failures, switch malfunctions, and even physical damage to network cables can disrupt connectivity.
Systems must be designed to anticipate and handle these failures. Without adequate error-handling strategies, even rare network faults can lead to disastrous outcomes, like deadlocked systems or data loss.
The common method to deal with these issues is using timeouts—waiting for a response for a certain period before giving up. However, timeouts don't provide information about what went wrong, making error handling complex.
Building Reliable Systems from Unreliable Components
One of the primary goals in distributed systems is to create a reliable system using unreliable components. Although this might sound counterintuitive, it has been a foundational concept in computing. Examples include:
Error-Correcting Codes: These allow data to be transmitted accurately across a noisy communication channel.
TCP Over IP: The Internet Protocol (IP) is inherently unreliable, as it can drop, duplicate, or reorder packets. The Transmission Control Protocol (TCP) adds reliability by ensuring that packets are delivered in the correct order and missing packets are retransmitted.
While we can improve reliability, there's always a limit. For example, if network interference is too severe, no error-correcting code can completely eliminate data loss.
Fault Detection in Distributed Systems
In a distributed system, detecting whether a node is operational can be challenging. Network uncertainties mean that nodes can fail in various ways, and often it's hard to differentiate between a network partition and a node failure. Some specific mechanisms can provide hints:
TCP Connection Feedback: When a node crashes or stops listening on a port, the operating system can respond with TCP RST (Reset) or FIN (Finish) packets. However, this mechanism isn't foolproof, especially if the node crashes mid-request.
Crash Notifications: If a node's process crashes while its operating system is still running, scripts can notify other nodes to reassign the crashed node's responsibilities promptly.
Despite these mechanisms, rapid feedback about a node's status is not always reliable. Retries and timeouts are commonly used strategies to handle unresponsive nodes. After multiple failed retries, the system may assume a node is dead. However, this assumption has a cost—declaring a node dead leads to redistributing its responsibilities, which can cause further strain on the system.
Timeouts and Unbounded Delays
A critical decision in distributed systems is setting appropriate timeouts for fault detection. Ideally, if there were guaranteed maximum delays for network communication (d) and request processing (r), the timeout could be set as 2d + r. Unfortunately, in asynchronous networks, delays are unbounded, making it difficult to predict a reasonable timeout value.
Network Congestion and Queuing: Network congestion and CPU queueing further exacerbate delays. When multiple nodes send packets to the same destination, the network switch queues the packets, introducing delays. Even upon reaching the destination, if the CPU is fully occupied, the operating system queues the incoming packets, adding more latency.
Adaptive Timeouts: Instead of using fixed timeouts, systems can adaptively adjust timeouts based on observed network round-trip times and variability (jitter). One method is using a Phi Accrual failure detector, as employed by systems like Akka and Cassandra. This dynamic approach helps balance the trade-off between timely fault detection and avoiding premature timeouts.
Unreliable Clocks
Distributed systems often rely on clocks for various functions, including message ordering and timeouts. However, clocks on different machines are rarely perfectly synchronized. Each machine's clock is a hardware device, and discrepancies occur due to factors like temperature and hardware imperfections.
Types of Clocks
Time-of-Day Clocks: These clocks return the current date and time. They are synchronized using the Network Time Protocol (NTP) to maintain consistency across machines. However, they can jump backward or forward if corrected by NTP, making them unsuitable for measuring elapsed time.
Monotonic Clocks: Monotonic clocks are used for measuring elapsed time. They guarantee a non-decreasing time value, making them ideal for measuring durations like timeouts. Unlike time-of-day clocks, they do not rely on synchronization and cannot go backward.
Clock Synchronization and Accuracy:
Synchronizing clocks across distributed systems is a complex task. NTP is commonly used but has limitations due to network delays and clock drift. For example:
Clock Drift: Quartz clocks in computers are prone to drift. Google assumes a clock drift of 200 parts per million (ppm), affecting accuracy even with frequent resynchronization.
Network Delays: NTP synchronization accuracy depends on network latency, which can vary due to congestion.
Leap Seconds: Inserting or removing a leap second can disrupt timing in systems not designed to handle them.
High-precision synchronization can be achieved using methods like the Precision Time Protocol (PTP) and GPS receivers, but they are often costly and complex to implement.
Consensus and Fault Tolerance
Quorums and Voting: In distributed systems, no single node can make critical decisions due to the possibility of failure. Instead, distributed algorithms often rely on quorums—a minimum number of nodes agreeing on a decision. This consensus mechanism ensures that even if some nodes fail or are temporarily disconnected, the system can still make progress.
Leader Election and Locking: To prevent conflicts, such as multiple clients accessing the same resource simultaneously, distributed systems often use leader election and locking mechanisms. A client must acquire a lease or lock from a lock service before accessing a resource. Fencing tokens can further enhance safety by ensuring that a node falsely believing it has exclusive access cannot disrupt the system.
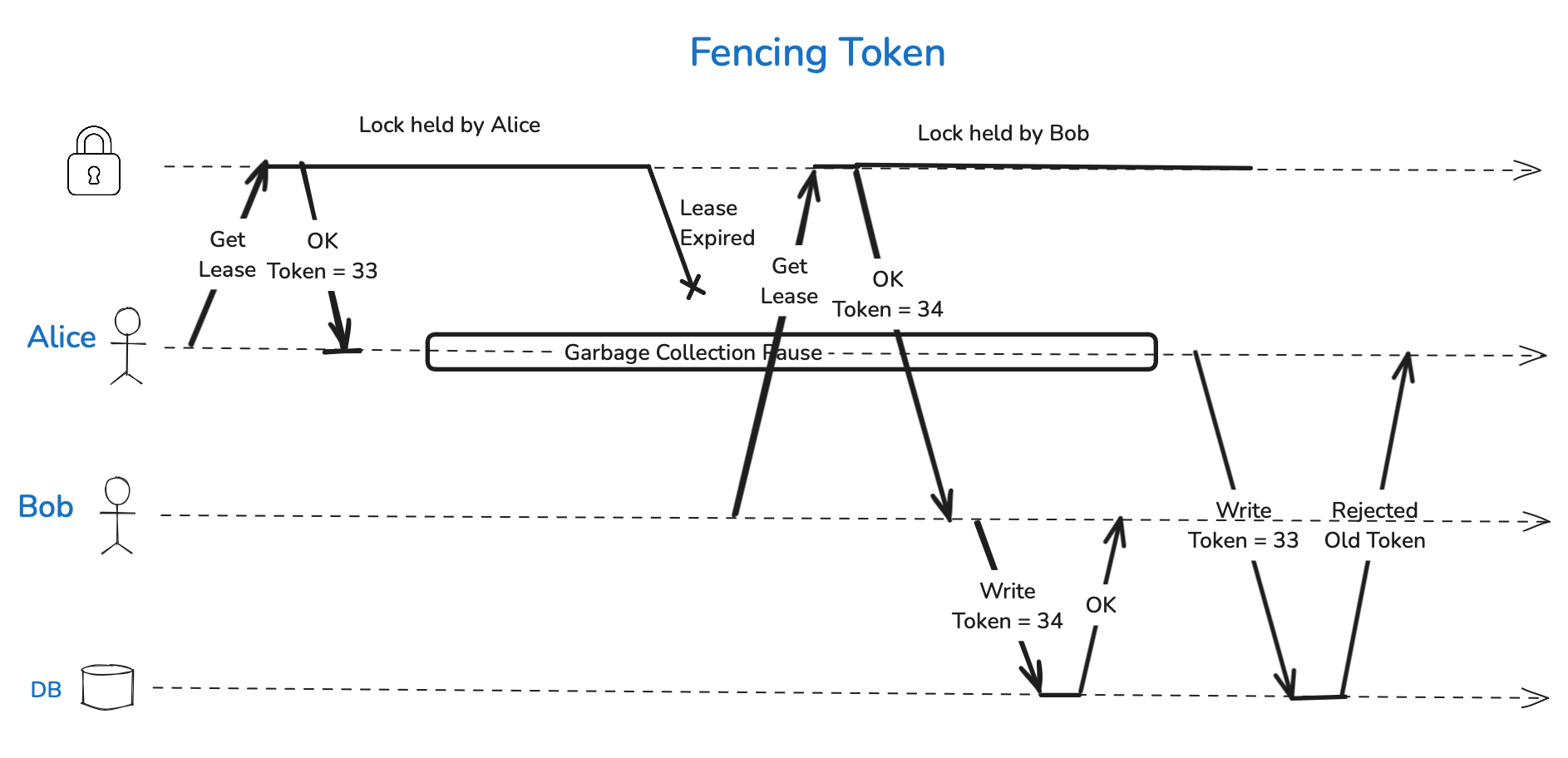
Fencing Tokens
In distributed environments, situations can arise where a node falsely believes it has exclusive access to a resource, leading to conflicts and potential data corruption. Fencing tokens are designed to mitigate this issue by providing a monotonically increasing value that can be used to verify the validity of a node's access to a resource.
Byzantine Faults
Byzantine Fault Tolerance:
While most distributed systems assume nodes are "unreliable but honest," Byzantine faults consider the possibility of nodes behaving maliciously or unpredictably. Byzantine fault-tolerant systems can continue operating correctly even when some nodes are compromised. However, designing such systems is complicated and costly, making them impractical for many use cases.
System Models
Distributed systems operate under different timing and failure assumptions:
Synchronous Model: Assumes bounded network delays, processing pauses, and clock errors. However, it is unrealistic for most practical systems where unbounded delays are common.
Partially Synchronous Model: The system mostly behaves synchronously but can occasionally exceed timing bounds. This model is more realistic and commonly used for designing distributed algorithms.
Asynchronous Model: Makes no timing assumptions and does not use clocks, making it restrictive but safer in the presence of unbounded delays.
Node Failures:
Crash-Stop: A node fails and never recovers.
Crash-Recovery: A node may crash and recover later. Its volatile state is lost, but stable storage remains intact.
Byzantine: Nodes can behave arbitrarily, including malicious behavior.
Summary
Distributed systems present a myriad of challenges due to unreliable networks, variable delays, and inconsistent clocks. Fault detection often relies on timeouts, but setting them appropriately is complex due to network unpredictability. Time synchronization is crucial but inherently unreliable due to clock drift, network delays, and leap seconds.
To build robust distributed systems, developers must consider partial failures and design protocols that can tolerate inconsistencies. Consensus mechanisms, adaptive timeouts, and fault detection strategies help achieve reliability. While scalability is often the primary goal, fault tolerance and low latency are equally important reasons for adopting distributed systems, making them indispensable in modern computing environments.
Copyright Notice
© 2024 trnquiltrips. All rights reserved.
This content is freely available for academic and research purposes only. Redistribution, modification, and use in any form for commercial purposes is strictly prohibited without explicit written permission from the copyright holder.
For inquiries regarding permissions, please contact trnquiltrips@gmail.com