
Database: Partitioning (Part 1: Consistent Hashing, Hybrid Partitioning and Secondary Indexes)
Database Partitioning for Optimized Performance and Efficient Data Management

Introduction
Database partitioning is the process of dividing a large database into smaller, more manageable parts called partitions. Each partition operates as an independent subset of the data while still being part of the overall database structure. The primary purpose of partitioning is to improve database performance, manageability, and scalability by optimizing query processing and efficiently handling large datasets.
As databases grow, they can encounter performance issues, especially with large tables that slow down queries and make maintenance operations more cumbersome. Partitioning helps alleviate these problems by allowing queries to target specific partitions, thus reducing the amount of data processed. It also enables more efficient resource management by distributing the load across multiple partitions, which is crucial for scaling databases horizontally across multiple servers or nodes.
Common use cases for database partitioning include managing time-series data in logging or monitoring systems, geo-partitioning for multi-region deployments, and isolating workloads in multi-tenant applications.
Partition with Replication
Partitioning divides the database into smaller segments (partitions), each containing a subset of the data. This allows the system to manage large datasets more efficiently by spreading them across multiple storage units or nodes. Each partition can reside on a different server or node in a distributed database system.
Replication involves creating and maintaining copies of the data (or partitions) across multiple nodes to ensure data availability, redundancy, and fault tolerance. If one node fails, the data can still be accessed from its replicas on other nodes. When partitioning and replication are combined, each partition is replicated across multiple nodes, ensuring that both partitioning and replication goals are met.
A node in a distributed database system can simultaneously hold leader (master) and follower (slave) replicas of different partitions. This configuration enhances resource utilization and fault tolerance. Below is a simplified diagram illustrating a system with three partitions (Partition A, B, and C) distributed across three nodes (Node 1, Node 2, and Node 3). Each partition has one leader and two followers, and the roles are distributed such that each node holds a mix of leader and follower replicas.
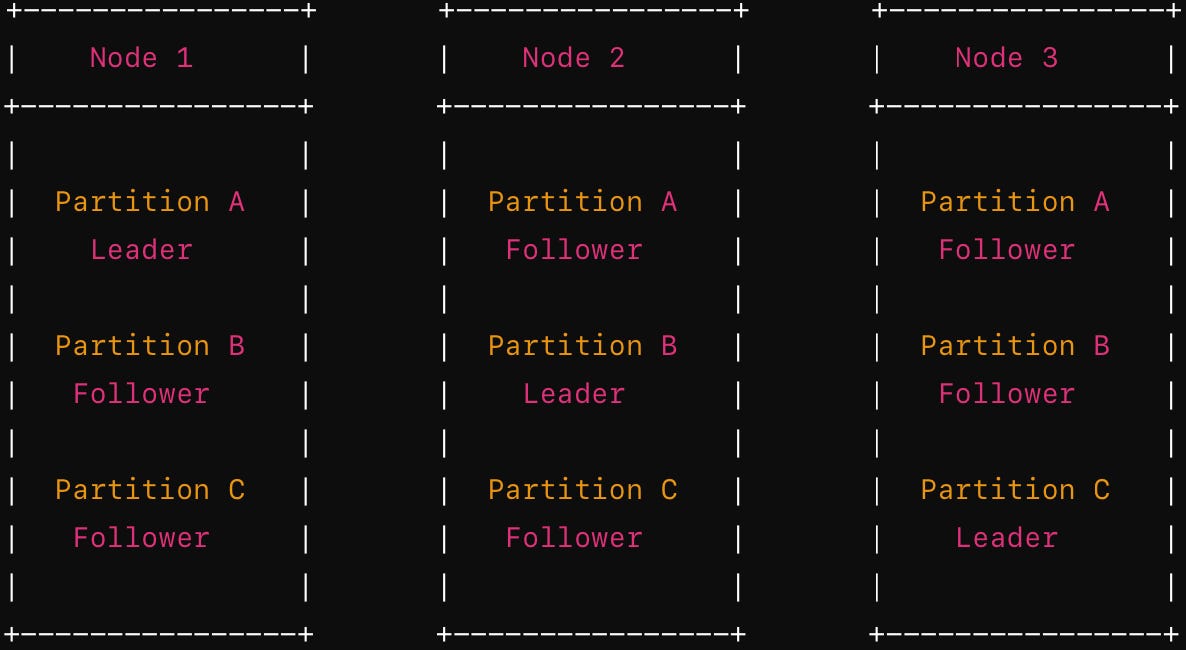
The selection of a partitioning strategy is generally separate from the choice of a replication method, so to keep things straightforward, we will not discuss replication in this blog.
Types of partitioning
Partitioning in key-value stores is essential for distributing data across multiple nodes in a distributed system. This section will explore the different types of partitioning strategies, starting with the simplest and moving towards more sophisticated methods like partitioning by key.
1. Random Partitioning
The simplest form of partitioning in a key-value store is random partitioning. In this approach, data is distributed across multiple nodes randomly without considering the key's value. This strategy is straightforward but often lacks efficiency and can lead to data skew and load imbalance.
2. Partitioning by Key Range
Partitioning by key is a more structured approach where the key itself determines the partition to which a key-value pair is assigned. Keys are ordered, and each node is responsible for a specific range of keys. In modern databases, determining the boundaries for key ranges in range partitioning involves careful consideration to ensure that data is evenly distributed across partitions.
2.1 Static Predefined Boundaries
Database administrators or system designers manually define the key ranges based on their understanding of the data distribution. This method is usually applied in environments where the key distribution is well understood and relatively static. The boundaries are set based on historical data or expected usage patterns.
2.2. Hash partitioning
Hash partitioning is a popular method used in distributed databases to evenly distribute data across multiple partitions (or nodes) by applying a hash function to the key of the data. The output of this hash function is a numeric value that is then used to determine the partition where the key-value pair should be stored. The general idea is to map keys to partitions in such a way that each partition stores roughly the same amount of data, thus avoiding the problem of some partitions becoming overloaded while others are underutilized.
Partition = h(key) mod N; where N = # partitionsChallenges
Range Queries: Hash partitioning is not ideal for range queries because the keys are distributed non-sequentially across the partitions.
Data Movement During Scaling: If the number of partitions changes (e.g., adding or removing nodes), significant data reshuffling might be required to redistribute the data evenly.
Complexity in Implementation: Implementing an efficient and collision-free hash function that evenly distributes data can be complex, particularly in systems with highly variable key distributions.
2.2.1. Consistent Hashing
In large-scale distributed systems, where nodes may be frequently added or removed, consistent hashing is often used because it reduces the amount of data that needs to be moved when the number of nodes changes.
Key idea: The key idea in consistent hashing is to treat the output of the hash function as a circular space or ring. The maximum value of the hash function wraps around to the minimum value, forming a circle.
Mapping Nodes to the Ring: Each node in the system is assigned a position on the ring by hashing the node’s identifier (e.g., its IP address). The position on the ring is determined by the hash value.
Mapping Keys to the Ring: Similarly, each key is hashed, and the resulting hash value is mapped to a position on the ring.
Assigning Keys to Nodes: A key is assigned to the first node that appears on the ring in a clockwise direction from the key’s position. This node is responsible for storing the data associated with that key.
Adding/Removing Nodes: When a new node is added, it is placed on the ring according to its hash value. Only the keys that would now fall under this node (i.e., between the new node and its predecessor on the ring) need to be moved to the new node. When a node is removed, its keys are reassigned to its immediate successor on the ring.
Example
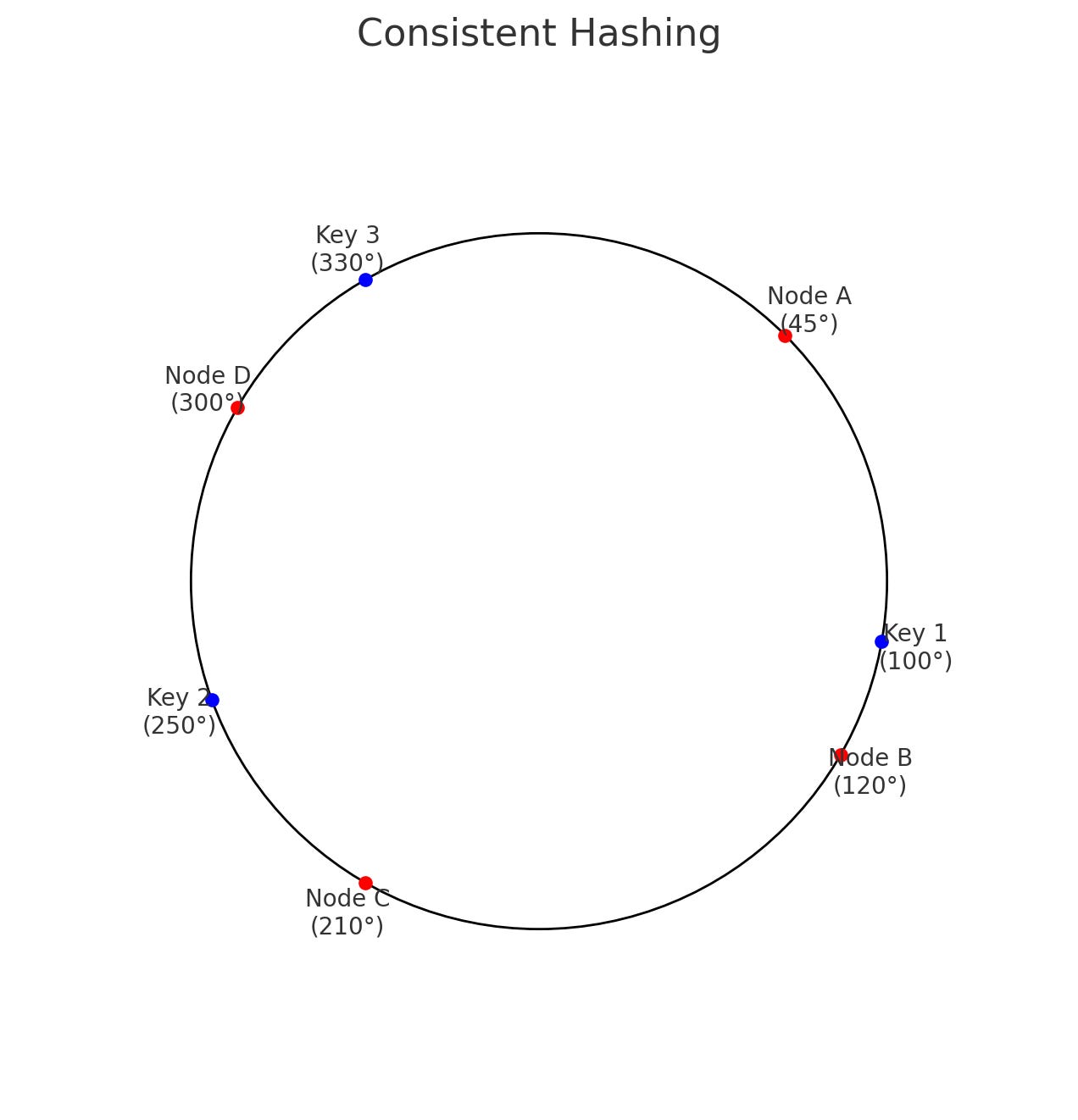
Let’s consider a simplified example with a consistent hash ring and four nodes (Node A, Node B, Node C, and Node D). Imagine the hash space is from 0 to 359, representing degrees on a circle. The hash function is used to place nodes on the ring.
Node A hashes to 45°.
Node B hashes to 120°.
Node C hashes to 210°.
Node D hashes to 300°.
Now, keys are hashed and placed on the ring.
Key 1 hashes to 100°: will be stored on Node B (the next node clockwise after 100°).
Key 2 hashes to 250°: will be stored on Node D (the next node clockwise after 250°).
Key 3 hashes to 330°: will be stored on Node A (as the ring wraps around, Node A is the first node after 330°).
Adding a Node: If we add Node E, and it hashes to 160°, the only keys that might need to be reassigned are those between Node B (120°) and Node E (160°). Any key in this range would move from Node B to Node E.
Removing a Node: If Node C is removed, the keys between Node B (120°) and Node D (300°) that were previously assigned to Node C (210°) would now be reassigned to Node D.
Consistent hashing is a powerful technique that enables distributed systems to handle node changes efficiently with minimal data movement. This method is widely used in systems like Cassandra, DynamoDB, and many distributed caching systems to maintain balanced data distribution and ensure scalability and fault tolerance.
Challenge
Hash partitioning is highly effective for distributing data evenly across nodes, but it poses challenges when it comes to executing range queries. Since keys are distributed across nodes based on the output of a hash function, they are not stored in any natural order, making range queries (e.g., finding all keys between k1 and k10) difficult to execute efficiently.
2.2.2. Hybrid Partitioning (Hash + Range)
However, modern databases have developed several techniques to overcome the limitation of hash partitioning and provide efficient range queries even when using hash partitioning. Hybrid partitioning combines the benefits of both hash and range partitioning to achieve efficient data distribution and support for range queries. Here’s is how it works:
Distributing Data Using a Hash Function: A hash function takes an input (in this case, a key) and produces a numeric output called a hash value. This hash value is then used to determine the partition (or node) where the data will be stored.
Organizing Data Within Each Hash Partition: Organize the data in sorted order within each partition to support efficient range queries.
How does range query work in hybrid partitioning ?
Suppose we want to perform a range query, system first determines which partitions might contain relevant data. Range query could span a single partition or multiple partitions, how do we find out which one it is ? the system typically follows a process that involves understanding the key distribution, the partitioning scheme, and the specific ranges assigned to each partition
Metadata Management: The system keeps track of which ranges of hash values or keys are assigned to each partition. This partition map is updated as partitions are added or rebalanced and is accessible to any node or client in the distributed system.
Parse the Range Query: System parses the range query to extract the start and end of the range, calculates the hash values for the start and end keys of the range. The system then consults the partition map to see which partitions correspond to these hash values ranges. The system checks if the start and end of the range fall within the same partition or span multiple partitions.
Query Execution Across Partitions: The system splits the original range query into sub-queries that target the specific partitions. Each partition processes its sub-query and returns the relevant data. The system then merges these results to provide a unified response to the original range query.
Cassandra uses the Murmur3 hash function to determine the partition for each key. Each node handles a specific range of hash values. Within each partition, Cassandra sorts data based on clustering columns, allowing efficient range queries within the partition.
Elasticsearch organizes data using inverted indexes, within each shard. These indexes allow for efficient range queries (e.g., finding all documents with timestamps between two values).
Clustering Columns
These columns determine the order of rows within a partition. Consider a table UserEvents that stores events associated with users, with the following schema:
CREATE TABLE UserEvents (
user_id UUID,
event_id UUID,
event_time TIMESTAMP,
event_type TEXT,
PRIMARY KEY (user_id, event_time, event_id)
);Partition Key:
user_id– This key determines which partition a row belongs to.Clustering Columns:
event_time,event_id– These columns determine the order of events within the partition defined byuser_id.
2.2.3. Index-Based Approaches
It’s similar to hybrid partitioning where data is distributed using a hash function. To support efficient range queries, additional data organization within each partition is necessary. The secondary index tracks the ordering of the keys, even though the primary data storage is unordered due to hash partitioning.
Using the same example as above, within each partition, secondary index could be created on the event_id (using B-trees) which orders the keys. Range query process remains the same as hybrid partitioning.
MongoDB often uses hash partitioning to distribute data across shards but supports secondary indexes that are B-tree-based. These indexes allow for efficient range queries on hash-partitioned data.
Partitioning Secondary Indexes by Document
Secondary indexes are built by associating each document (or record) with its corresponding partitions, meaning that the index entries related to a particular document are stored together, often on the same node that holds the primary document. This means that querying the index and retrieving the corresponding documents can be done efficiently within the same partition.
Challenges: The secondary index may become large and require significant storage. If a query spans multiple partitions, the system still needs to merge results from different nodes.
Partitioning Secondary Indexes by Term
Secondary indexes are organized by terms (or attributes) rather than by document. Instead of co-locating the index entries with the documents, the index entries are distributed across the nodes based on the terms. The secondary index is then hash-partitioned by term, meaning that index entries for different terms are distributed across nodes. For example, all documents with a timestamp of 2024-08-10 might have their index entries stored on Node A, while all documents with a timestamp of 2024-08-11 might have their index entries stored on Node B.
Challenges: Requires additional lookups, as the document and its corresponding index entry may be on different nodes.
Conclusion
In this first part of our exploration into database partitioning, we've delved into the critical techniques of Consistent Hashing, Hybrid Partitioning, and the role of Secondary Indexes. These strategies are essential for distributing data efficiently across nodes, ensuring scalability, and maintaining high performance in distributed systems. Consistent Hashing offers a dynamic and fault-tolerant approach to data distribution, while Hybrid Partitioning combines the strengths of multiple strategies to handle diverse data scenarios. Secondary Indexes further enhance query performance by providing a mechanism to access data beyond the primary key.
In the second part of this blog, we will dive deeper into the operational aspects of partitioning, the techniques for Rebalancing Partitions to handle data growth and load imbalance, and the critical role of Request Rerouting in ensuring efficient data access, including how ZooKeeper facilitates coordination in distributed systems.
Copyright Notice
© 2024 trnquiltrips. All rights reserved.
This content is freely available for academic and research purposes only. Redistribution, modification, and use in any form for commercial purposes is strictly prohibited without explicit written permission from the copyright holder.
For inquiries regarding permissions, please contact trnquiltrips@gmail.com