
Database: Indexes (part 1)
An index is a data structure that improves the speed of data retrieval operations on a database at the cost of additional storage space and slower writes

Indexes allow the databases to find specific rows or ranges of rows quickly. Indexes require additional storage space beyond the actual data in the table. This space is used to store the index structure itself and possibly additional metadata. Whenever data in the table is modified (inserted, updated, or deleted), indexes also need to be updated to reflect these changes. This maintenance overhead can impact write operations.
Relationship to Storage Engines
A database's storage engine is responsible for managing how data is stored, accessed, and manipulated on disk. When a query is executed, the storage engine uses the index to determine the most efficient way to access the underlying data. Different storage engines support different types of indexes. For example, B-trees are commonly used in traditional relational databases, whereas LSM-trees (Log-Structured Merge-trees) are popular in NoSQL databases like Cassandra or RocksDB.
Simple Key-Value Storage Engine
Imagine a simple database stored as a text file where each line contains a key and a value separated by a comma. Value can be anything including a document. For example:
apple,fruit
car,vehicle
book,objectPros: Writing new data is simple and fast (just add a new line) - O(1)
Cons:
To find a value for a given key, you need to read through the entire file line-by-line until you find the key. This is inefficient for large files - O(n)
Updating or deleting a key requires rewriting the entire file, which is slow.
As the file grows, operations become slower.
Using Indexes to Improve Performance
An index in a key-value storage engine is a separate data structure that keeps track of the positions of keys within the main data file. This allows for faster lookups because you can quickly find the location of a key without reading the entire file.
How to Use the Index ?
Creating the Index: When adding a new key-value pair, also update the index. Any kind of index slows down the writes because the index has to be updated on every write.
Retrieving Data: Look up the key in the index file to find its position. Use the position to quickly access the key-value pair in the original file.
Different databases support various types of indexes to optimize data retrieval and storage. Here are some common types: Hash Indexes, Spatial Indexes, Bitmap Indexes, Full-Text Indexes, Primary Indexes, Secondary Indexes, Composite Indexes, and so on. Choosing the right indexing depends on the application’s query patterns.
Indexing Everything?
Databases do not index everything by default for several reasons:
Storage Overhead: Indexes consume additional storage space
Write Performance Impact: Every insert, update, or delete operation requires updating the relevant indexes, which can slow down write performance
Types of indexes in modern databases
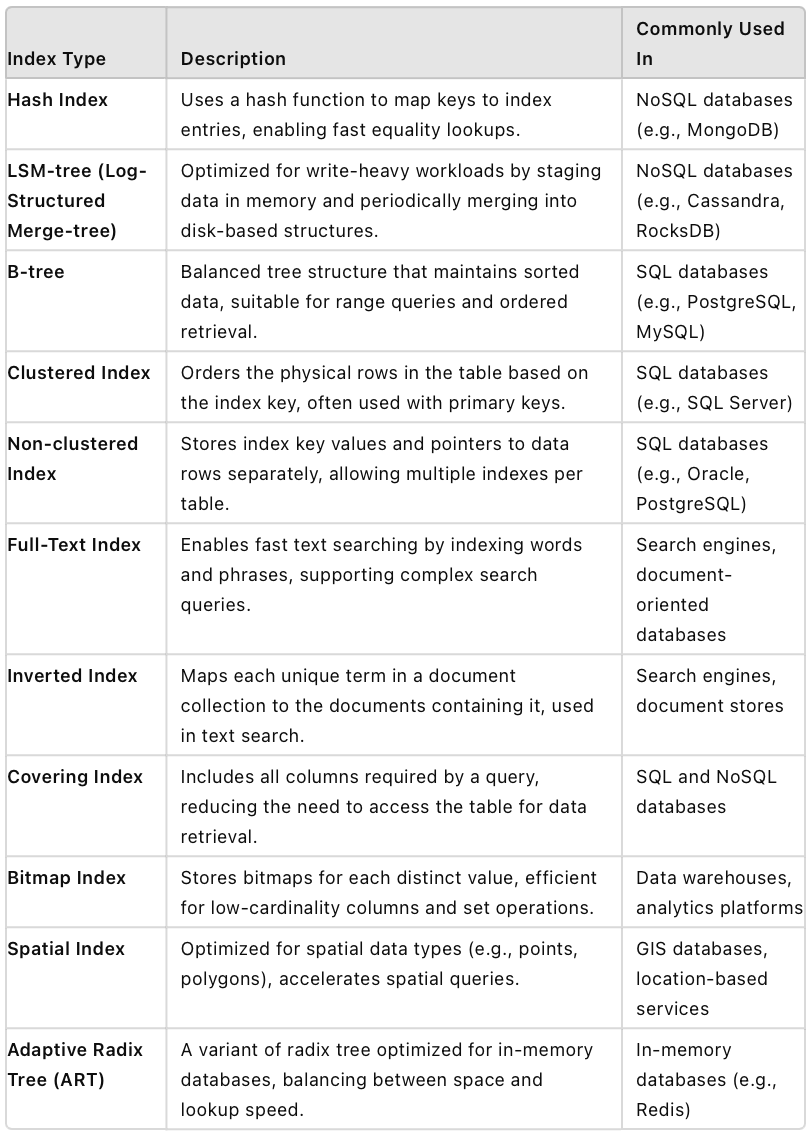
In this blog series, we will explore various types of indexes including Hash Indexes, LSM-trees, B-trees, and more, exploring their structures, applications, and performance characteristics.
1. Hash Index
In a simple key-value storage engine where data is stored by appending key-value pairs to a file, a hash index can significantly improve read performance. The basic idea is to maintain an in-memory hash map that maps each key to its byte offset in the data file. This allows for quick lookups by leveraging the efficiency of hash maps.
Example:
Data is appended to a file, with each line containing a key-value pair. Below is the example database

An in-memory hash map keeps track of the byte offset for each key.
{
"apple": 0,
"car": 12,
"book": 24
}When a new key-value pair is added, it is appended to the file. The hash map is updated with the new key and its byte offset.

How does the data file segmentation work ?
Segmentation involves splitting the data file into smaller, more manageable pieces, known as segments. Segment files are immutable; new data is always written to new segments. Over time, as keys are updated, old segments may contain obsolete or duplicate entries for keys. Compaction removes these obsolete entries, merging segments and freeing up space.
Compaction Process:
A background thread reads multiple old segments.
It merges the data, keeping only the most recent value for each key.
After merging, the system switches read requests to the
merged_segment.Old segments can be deleted or archived.
While merging is happening in the background, the system continues to serve read and write requests using the old segments. If a read request for a key happens while it is in the process of being written to a new segment, the system can handle it by checking the new segment after the old segments.
Example
Segment 1 contains initial key-value pairs and Segment 2 contains additional key-value pairs and Segment 3 (active segment) is the current segment where new writes are being appended.
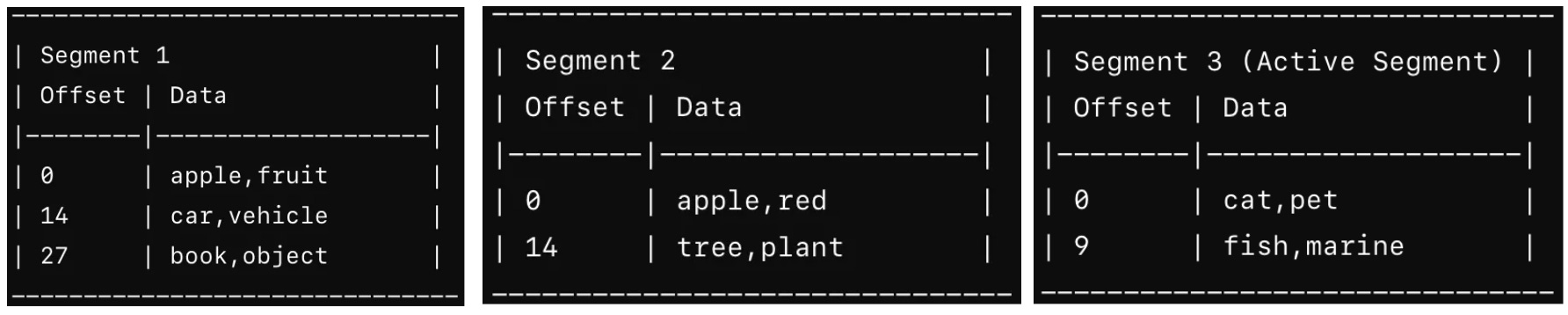
A background thread merges Segment 1 and Segment 2 into a new merged segment. During merging, duplicates are handled by keeping the latest value
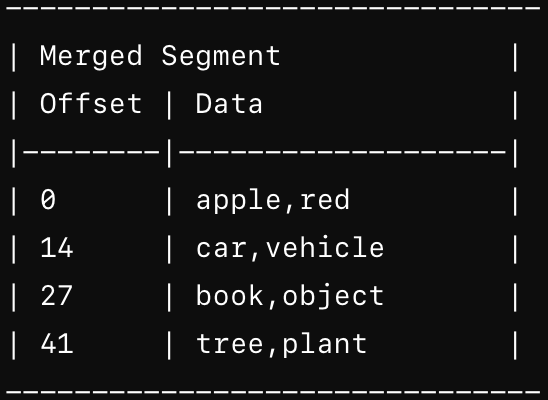
Each merged segment has its own hash table mapping keys to file offsets, allowing for quick lookups by checking the most recent segment first. Reads and Writes are directed to the active segment after the compaction process. If a key is not found in the active segment, during a read, it checks the previous Merged Segments.
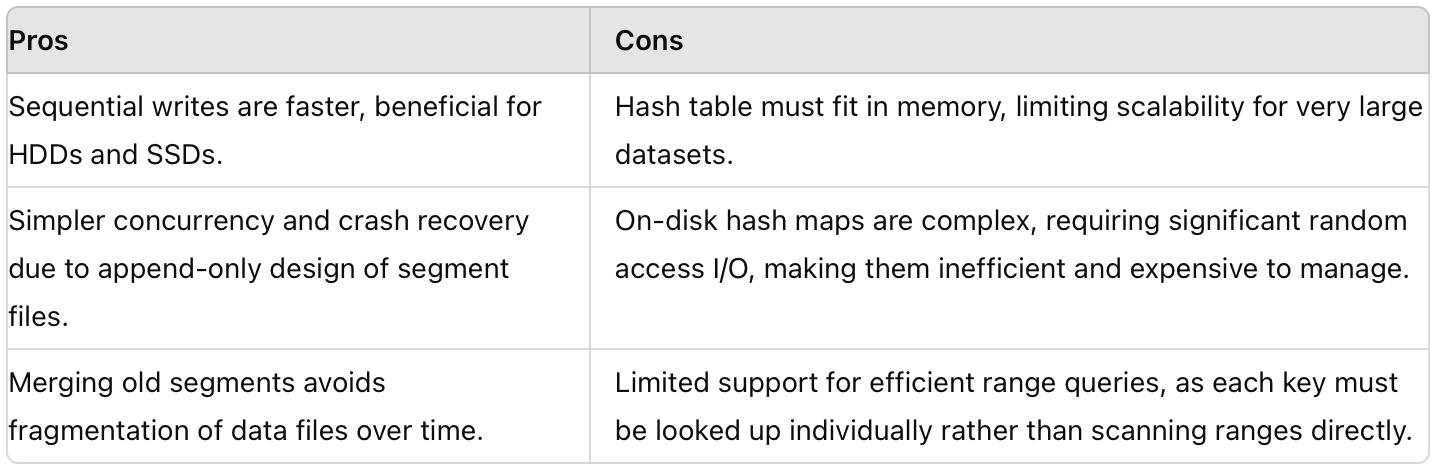
Pros and Cons of Hash index
2. SSTables
Sorted String Tables, are a type of on-disk data structure used for storing and retrieving key-value pairs efficiently. They are designed to address some limitations of simple Hash index based log segments. SSTables are typically organized as immutable files sorted by keys. This sorted order allows for efficient range queries and sequential scans, but the merge and compaction step exists in SSTables as well.
Key Characteristics:
Immutable: Once written, an SSTable does not change. Updates and deletions are handled by writing new SSTables with the changes.
Index: SSTables often include an index structure (like a block index or bloom filter) that helps quickly locate key offsets within the SSTable file.
Sequential Access: Data is stored in sorted order, enabling efficient range queries and scans, which are common in many database operations.
Reduced Seek Time: Unlike hash-based structures where data can be scattered across the storage medium, SSTables minimize seek times by storing related data close together on disk.
Compaction process: SSTables facilitate efficient merge operations during compaction processes (similar to merge step in merge sort). Merging sorted files is faster and less error-prone compared to managing hash collisions or handling variable-length records.
Block Index Structure
SSTables often use a in-memory block index to facilitate efficient key retrieval, which is usually an array of entries. Each entry in the block index corresponds to a block of data within the SSTable. Entries in the block index typically contain:
Key Range the range of keys covered by the block.
Offset: The offset within the SSTable file where the block starts.
Example:
Suppose we have an SSTable containing the following key-value pairs (keys are sorted):
Key: "apple", Value: "red"
Key: "banana", Value: "yellow"
Key: "grape", Value: "purple"
Key: "orange", Value: "orange"
# The Block Index might look like this:
[ ("apple", offset_1), ("grape", offset_2) ]Here, offset_1 and offset_2 are the starting offsets in the SSTable file where the blocks containing keys "apple" and "grape" begin, respectively.
To find a specific key, such as "banana", run binary search on the block index to determine which block contains the key "banana" and run binary search within the block (if it's sorted) to locate the exact key-value pair - O(log n)
Compaction in SSTables
Compaction processes are crucial for maintaining performance and managing storage space in SSTables. Typically, SSTables are periodically merged to reduce the number of files and improve read/write efficiency. After merging SSTables, a new block index is created for the resulting compacted SSTable.
Construction of SSTables
As key-value pairs are inserted into the SSTable, they are sorted by key. This sorting ensures that keys are stored in lexicographical order within the SSTable, but how do you insert a new key-value pair into SSTable such that you can still retrieve keys in sorted order ?
What data-structures come to mind ?
The choice of data structure for reading keys in sorted order depends on whether the data is stored in memory (RAM) or on a hard disk (or any persistent storage).
In-Memory (RAM): Binary Search Tree (BST), Balanced Binary Search Tree (e.g., AVL Tree, Red-Black Tree). In-memory data structures like BSTs are optimized for fast access and manipulation in RAM, leveraging the CPU's cache hierarchy for maximum performance.
Hard Disk (Persistent Storage): B-tree, B+ tree. Disk-based data structures like B-trees are optimized for minimizing disk I/O operations.
When comparing the speed of operations between in-memory data structures (like BSTs) and disk-based data structures (like B-trees), in-memory operations are typically faster because they leverage the faster access times of RAM and avoid the latency associated with disk I/O. Hence,
A newly inserted key-value pairs are often first written to an in-memory buffer (also called a memtable) to optimize write performance and facilitate efficient data ingestion into SSTables.
Once the memtable reaches a certain size threshold, it is flushed to disk as an SSTable.
SSTables are usually written as immutable files on disk, which means once written, they do not change.
As the SSTable is written or during compaction, an in-memory index (like a block index) is built to map key ranges to file offsets.
Originally this indexing structure was described as Log-Structured Merge-Tree.
Contiguous Storage SSTables
When an SSTable file is written to disk, it is typically written as a single, contiguous file. This means that the entire 1GB SSTable file is stored in a continuous sequence of disk blocks. This contiguous storage helps in:
Efficient Sequential Reads: Since the data is stored contiguously, sequential reads (e.g., range queries) can be performed efficiently with minimal disk seek operations.
Limitations of SSTables
Database crash: if a database crashes while a memtable is still in memory, the data in the memtable can be lost. Modern database systems typically employ several strategies to protect against data loss due to crashes. Here’s a detailed look at what happens to the current memtable if the database crashes and how databases handle this situation:
Write-Ahead Logging (WAL): before any changes are made to the memtable, they are first written to a Write-Ahead Log (WAL). The WAL is an append-only log file that records every operation that will be applied to the memtable. In case of a crash, the operations can be recovered and reapplied to reconstruct the memtable. This log is deleted when the corresponding memtable is written to SSTable.
Inefficiency in Reading a Non-Existent Key: When you attempt to read a key from an SSTable that doesn’t exist, the system performs a binary search on the index block to find the position of the key. If the binary search in the index block suggests that the key might be within a certain range, the system then accesses the corresponding data block. These steps require multiple disk accesses, making the process slow and resource-intensive, especially if the key is absent.
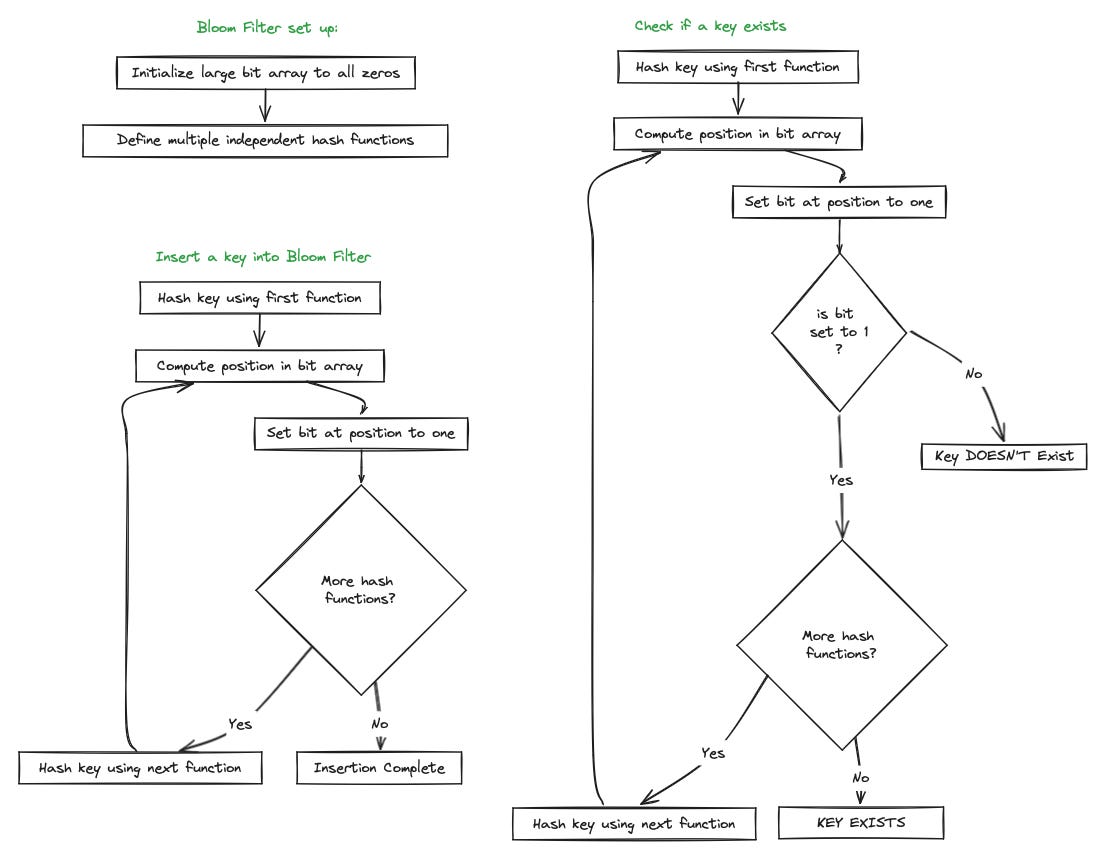
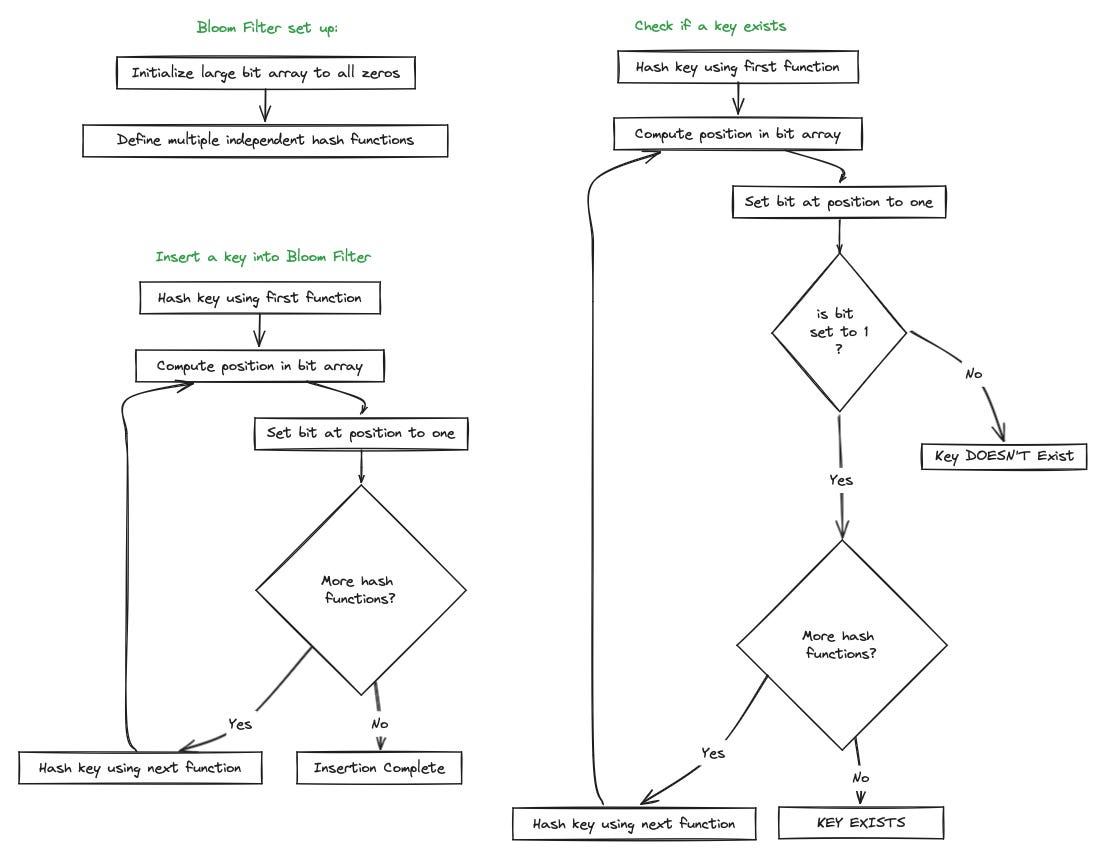
Bloom Filter: is a space-efficient probabilistic data structure used to determine if a key is definitely not present in the SSTable, reducing unnecessary disk reads. A Bloom Filter uses a large bit array, initially set to all zeros. Multiple independent hash functions map a key to multiple positions in the bit array. When a key is inserted into the Bloom Filter, each hash function computes a position in the bit array. The bits at these positions are set to one. When checking if a key is present, each hash function computes the positions in the bit array, if all the bits at these positions are set to one, the key might be present. If any bit at these positions is zero, the key is definitely not present.
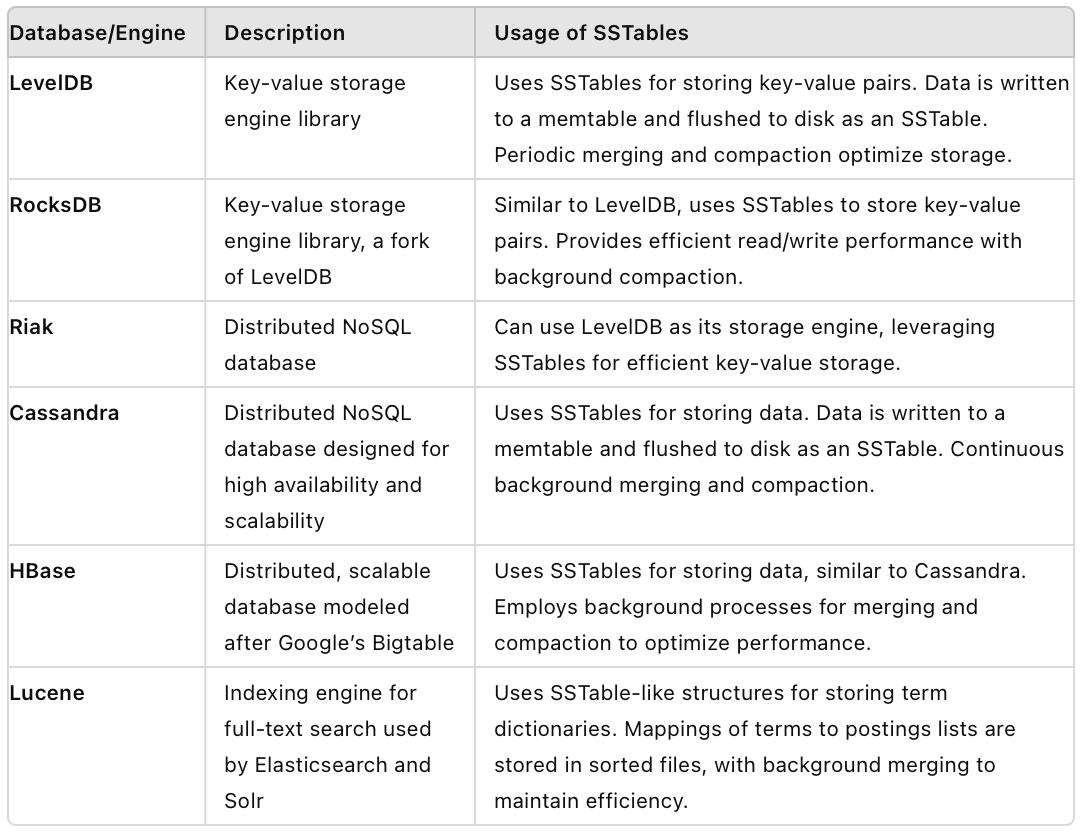
SSTables in Modern Databases
3. B-tree index
In the context of key-value stores in databases, B-trees are widely used to manage the keys and efficiently locate the associated values. A B-tree (Balanced Tree) is a self-balancing tree data structure that maintains sorted data and allows searches, sequential access, insertions, and deletions in logarithmic time.
Node Structure in B-trees
Each node is structured to hold a fixed number of keys (based on the node size, often a disk page size like 4 KB). For internal nodes, each key is associated with a pointer to a child node. Keys within each node of a B-tree are stored in sorted order. This allows for efficient searching using techniques like binary search. For leaf nodes, each key is associated directly with a value or a pointer to where the value is stored.
Nodes are stored on disk to manage larger datasets efficiently. Modern databases use caching mechanisms to keep frequently accessed nodes in memory. In leaf nodes, values can be stored inline with keys or as pointers to data stored elsewhere, depending on the database design and performance considerations.
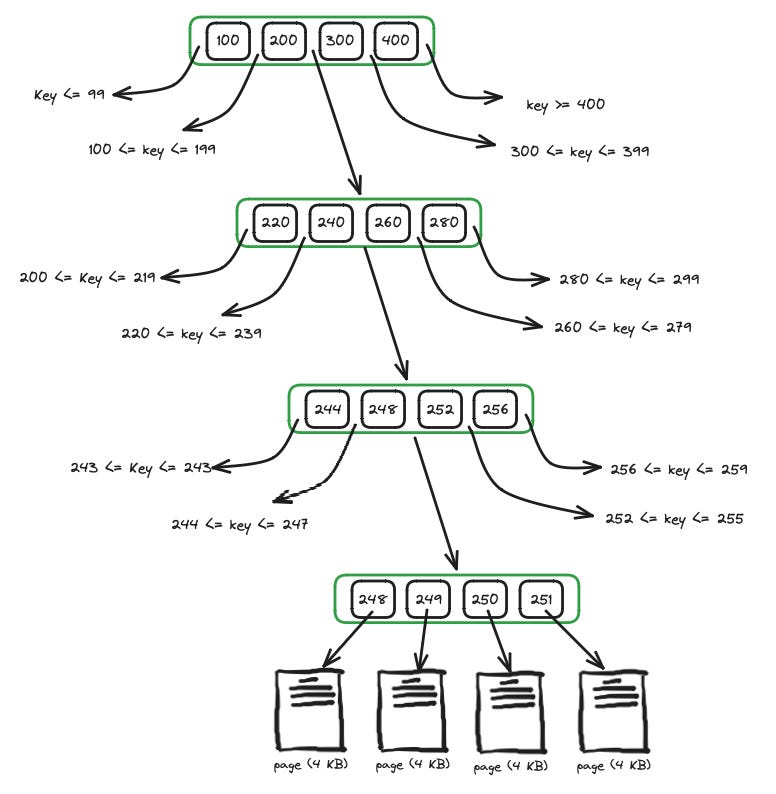
Branching Factor
The branching factor in a B-tree refers to the maximum number of child pointers (or references) that each internal node can have. It determines how many keys a node can hold before it splits into multiple nodes, thereby maintaining the balance and efficiency of the tree structure.
Retrieval of Key
Start from the root node and compare the search key with the keys in each node to determine the appropriate child node to traverse (using binary search).
Follow pointers or references in each node until reaching a leaf node containing the desired key-value pair.
Once at the leaf node, if the key is found, retrieve the associated value directly from the leaf node.
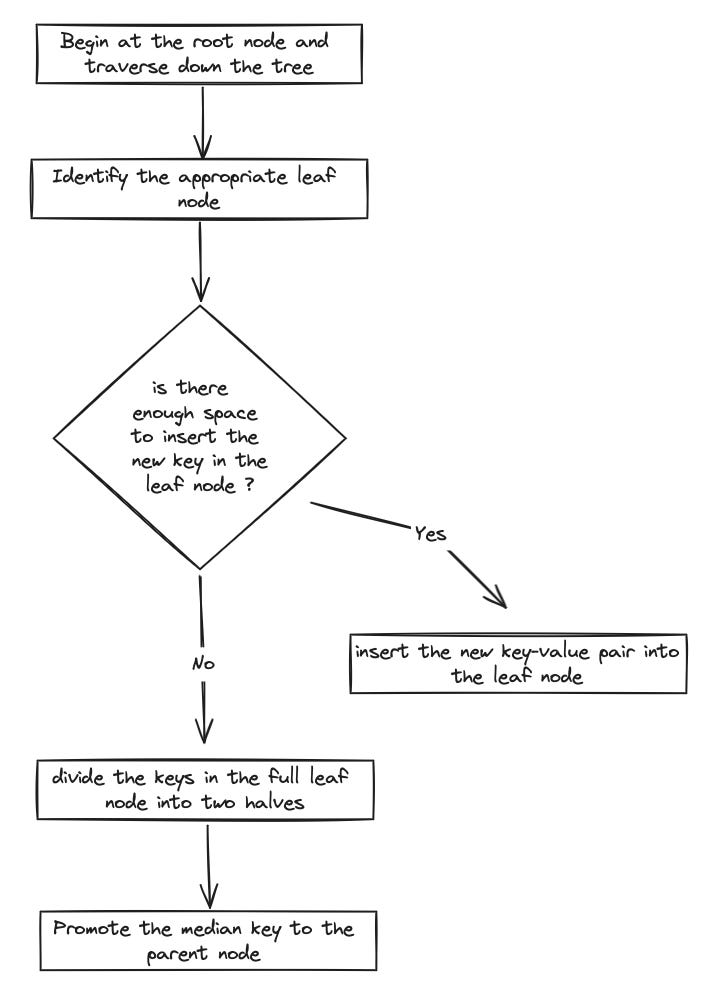
Inserting a key-value pair
Begin at the root node and traverse down the tree based on comparisons with the keys stored in each node.
Once the appropriate leaf node is identified, check if there is enough space to insert the new key without violating the maximum capacity.
If the leaf node has space, insert the new key-value pair into the leaf node while maintaining the sorted order of keys.
Otherwise, divide the keys in the full leaf node into two halves (two new leaf nodes, ensuring each new leaf node maintains its sorted order of keys). Promote the median key to the parent node and adjust pointers or references in the parent node to point to the newly created leaf nodes
Write-Ahead Logging (WAL) is used to avoid data inconsistencies in case of a database crash.
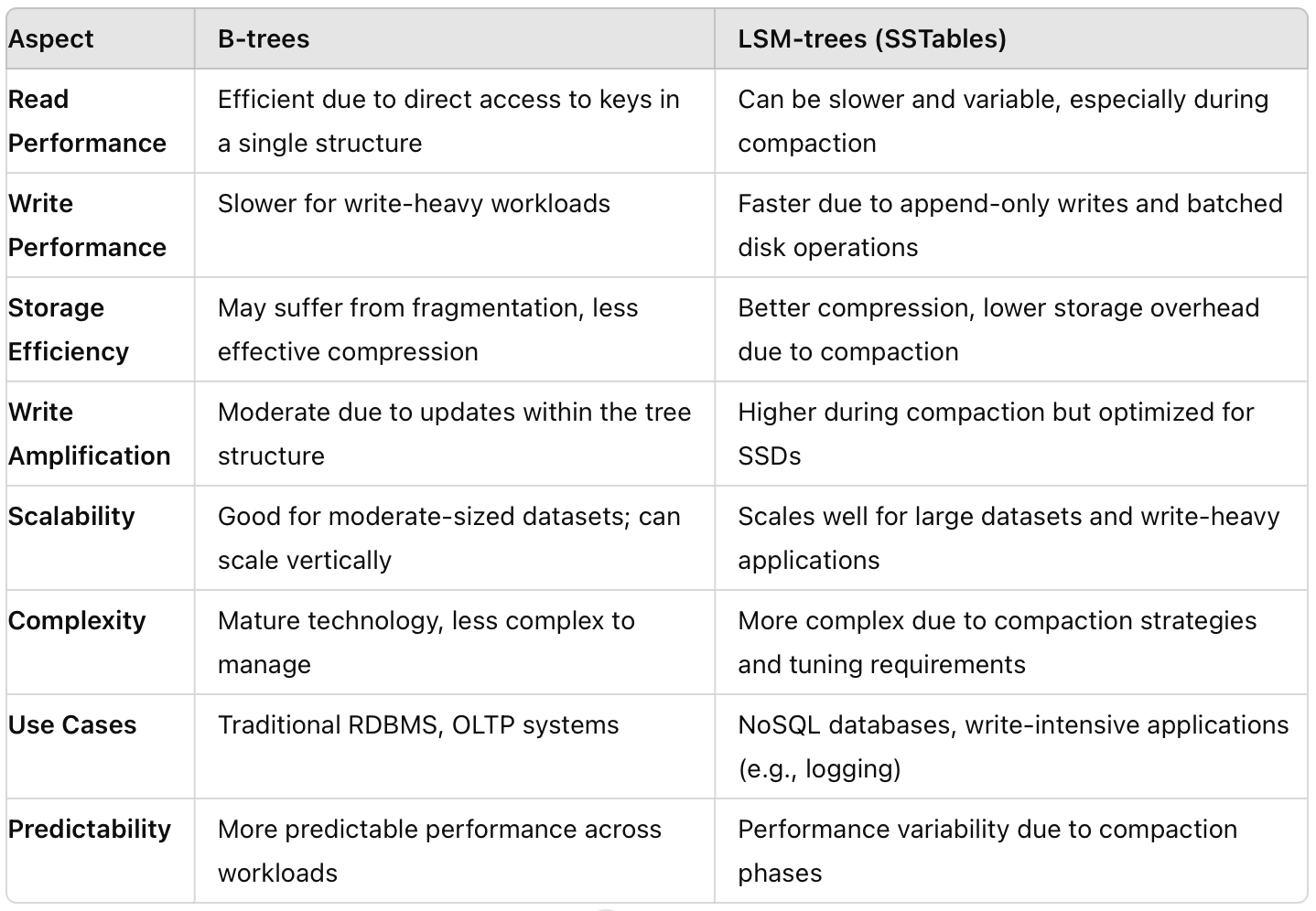
B-tree vs LSM-tree
Conclusion
Stay tuned for our next blog post where we will delve into the details of the remaining index types. We'll explore their functionalities, optimizations, and real-world applications to provide a comprehensive understanding of indexing strategies in databases.
Copyright Notice
© 2024 trnquiltrips. All rights reserved.
This content is freely available for academic and research purposes only. Redistribution, modification, and use in any form for commercial purposes is strictly prohibited without explicit written permission from the copyright holder.
For inquiries regarding permissions, please contact trnquiltrips@gmail.com